


BAR-K9Behavioral Autonomous Robotic K9Primary Objective
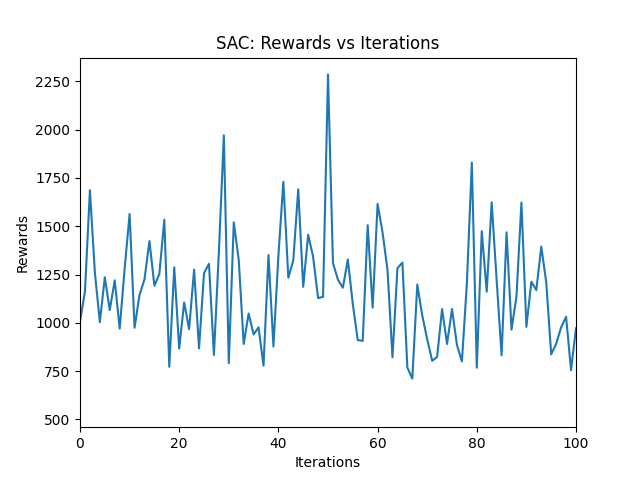
Soft Actor-Critic (SAC) and Deep Q Learning (DQL)
Making use of RL to navigate uneven and rough terrains


RL Training Framework

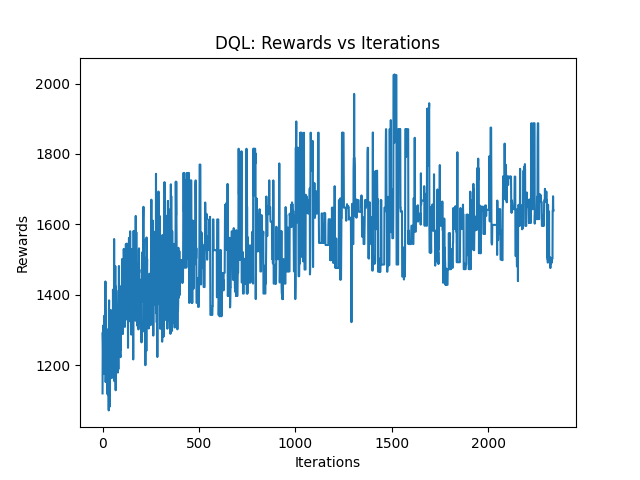
DQL OVERVIEW

Store experiences in a replay buffer
Collect transitions through interaction
Update Eval-Net using sampled experiences and back propagation
Periodically copy Eval-Net weights to Target-Net
OUTCOME?
adapt dynamically to rough terrains,optimizing stability and path efficiencyGOAL ?
maximize entropy (exploration) while also trying to maximize the reward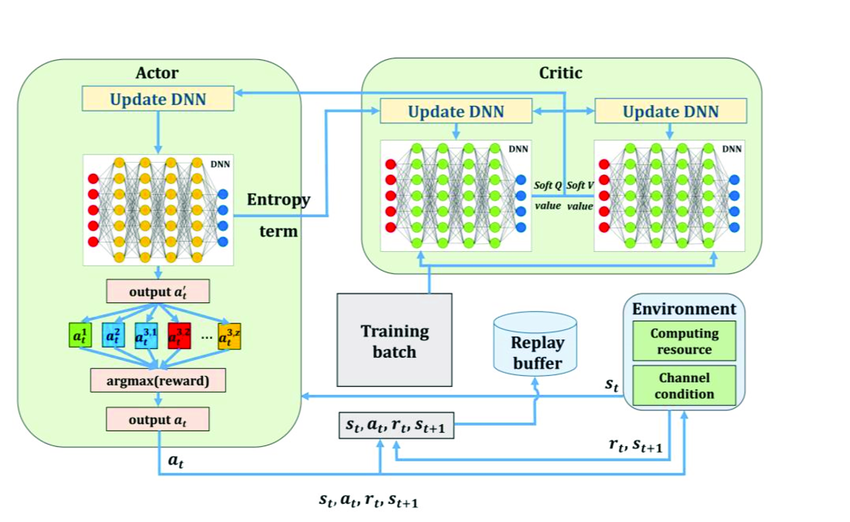
SAC OVERVIEW
Actor: Policy that determines actions given the current state.
Critic:
Used to estimate state-action values.
Two critics are trained independently to avoid overestimation of Q-Values
Replay Buffer: Stores information on state, action, reward, and next state.
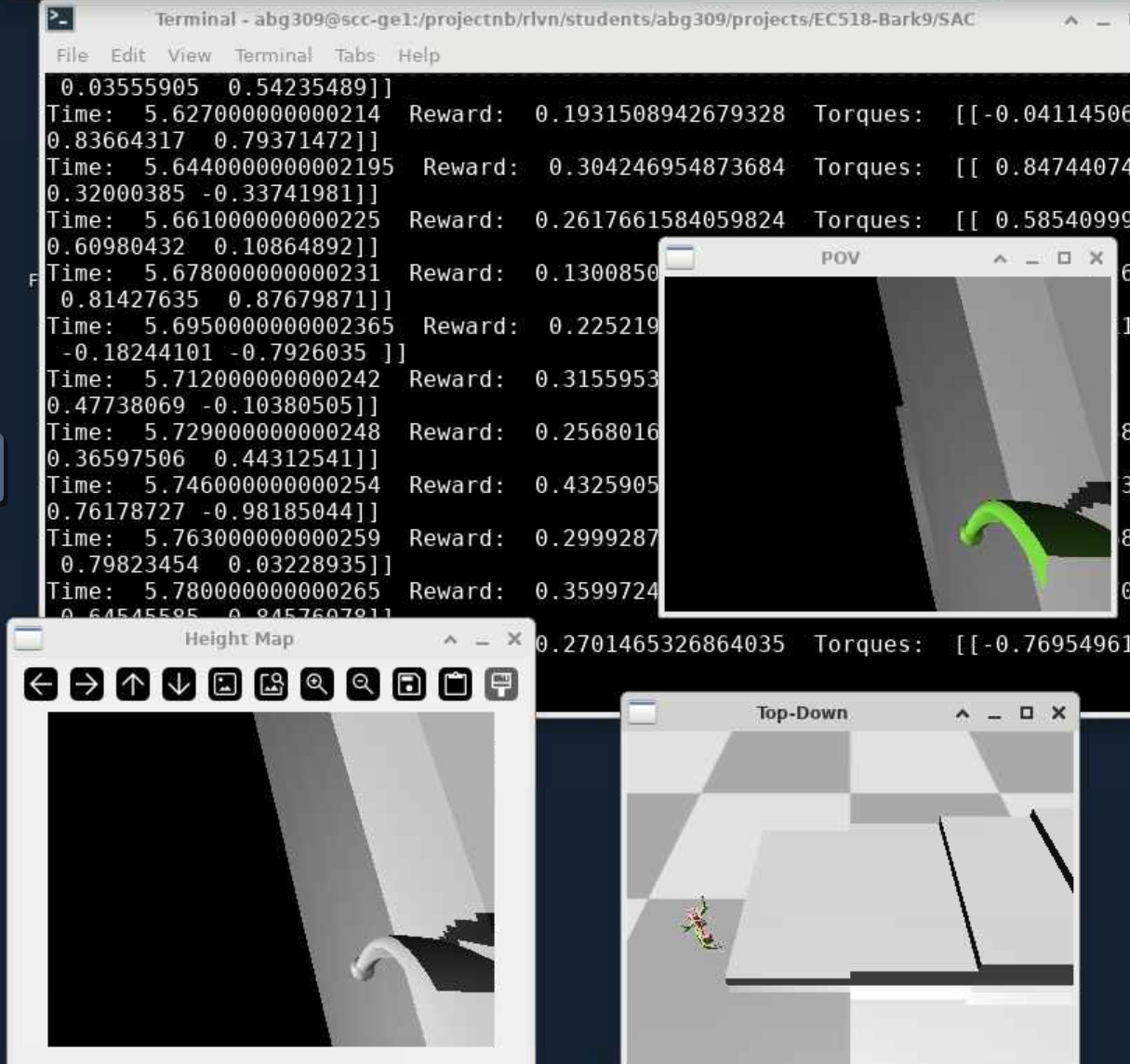
sim2Real
The quadrupeds XML were first modeled and then transferred to MuJoCo (physics simulator) to perform RL training

➡️


PATRIQ robot XML model
RL Training


ROBOT XML DESCRIPTIONS
➡️

adaptation of Google Barkour v0 into MuJoCo
Terrain Adaptation

uneven rough terrain 
minimal friction slope

stairs
grids